
By Mette Fog Olwig as part of the NEPSUS Series
New Partnerships for Sustainability (NEPSUS) is a Tanzanian-Danish research project that involves fifteen researchers with different disciplinary backgrounds and expertise. This is a great strength but, at the same time, a challenge. It was therefore not without some concern that I took on the role of organizing a workshop aimed at coding qualitative data with NVivo (specifically NVivo 12). NVivo is a software which supports the organization, coding and analysis of qualitative data. It can be challenging for researchers to analyze qualitative data if they usually work with quantitative data.
Furthermore, NVivo has several features that can lead to a rather quantitative analysis. This is problematic if the qualitative data used has not been collected in a statistically significant manner. A central challenge to the workshop design was therefore to organize an NVivo coding process that ensured an inductive and qualitative approach to the analysis. Having now worked through the process, I would like to share my experiences as they may be useful to other large, interdisciplinary research teams.
NEPSUS does not have the option of using NVivo for Teams because of unreliable internet and cost requirements. If practical, however, NVivo for Teams allows participants to work simultaneously on a single NVivo project file on one server. In NEPSUS, we instead worked asynchronously on individual NVivo project files. We used analytical codes (explained later), not purely thematic codes. Furthermore, we only coded the sentences that we considered relevant to the analysis. This means that although every sentence is of course read as part of the coding process, not necessarily every sentence is coded. In my experience, this saves time as coding thematically, and coding every sentence, can easily transform the analytical process into a mechanical one.
Why Coding?
The project includes various sources of quantitative and qualitative data and it can be difficult for all members of the team to understand and benefit from all the data. Even though it is not an easy task to coordinate a coding process that involves more than ten researchers, it proved significantly useful. After coding, it is much easier for all members of a research group to find and use relevant qualitative data. Another advantage we identified was that the preparation process for coding led to important conversations concerning synergies, analysis, definitions and interpretation of data among the team members.
Step 1: Organize and Clean the Qualitative Data
Before coding, all the qualitative data, including key informant interviews, focus group discussions, participant observations and secondary documents, need to be in their final form and well organized. This means:
- All the qualitative data is organized in folders in a logical way that is clear to everyone who will be coding.
- Interviews are transcribed as correctly as possible
- All files are free of grammatical errors and spelling mistakes
- All background information is included in the relevant file (such as name of interviewees, date recorded, etc.). NEPSUS has collected data pertaining to three different natural resource sectors, wildlife, coastal resources and forestry. We prepared Excel sheets for each sector – see image below for an example of the information recorded for each instance of participant observation in the forestry sector.

Step 2: Organize a Coding Workshop/Retreat
Coding is not just a process of organizing data, it is also an analytical process. This means that the organization of data will depend on the analytical approach that is adopted. In order for the researchers involved in coding to establish and work with a common analytical framework, joint preparation is crucial. We organized a one-week workshop in Bagamoyo, Tanzania, located a few hours’ drive from Dar es Salaam, where most of the researchers live. Since they have many other work obligations, it was important to gather the participants in a location far enough from their workplace so that they would not be disturbed.

Step 3: Create a Codebook
The first part of the workshop was concerned with developing a codebook. A codebook is an overview of all the relevant codes and their descriptions. In NVivo, it is possible to work with first-level codes, often referred to as parent nodes. These parent nodes can then contain subthemes that are called child nodes. A parent node includes the information from all the child nodes as well as any information that has been coded to the parent node, but not a child node. We chose to use Excel for our codebook (see image below for an excerpt from the codebook). It is also possible to create a codebook directly in NVivo. In this case, you first create all the parent nodes and child nodes in NVivo and then export the structure as a codebook. However, when discussing and editing the codebook as a group, I considered the Excel format to be easier to use.
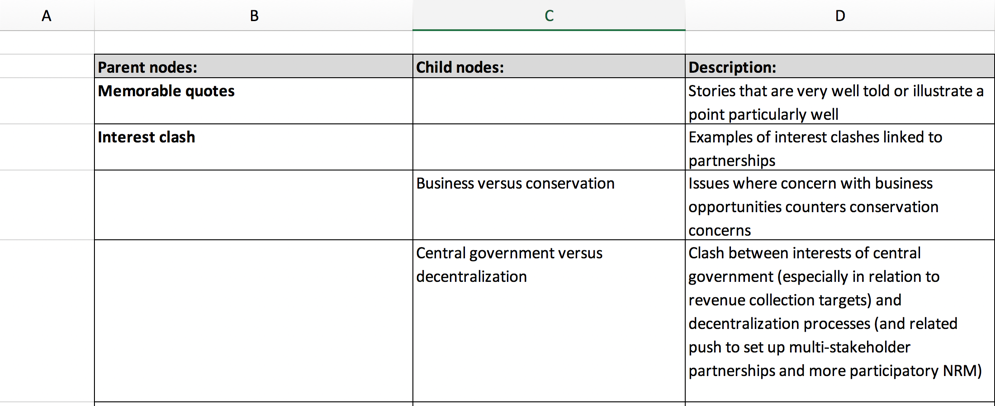
We decided to work only with codes that were central to our analytical foci and agreed on avoiding the creation of purely descriptive codes. The aim was to end up with approximately 50 parent nodes. Even when there is a codebook, it is difficult for the coder to remember that the codes exist if there are too many. In order to select the appropriate codes, we adhered to the following procedures:
Do not code unnecessarily
We did not include codes for information that we did not need to look for in the qualitative data. For example:
- If the information is common knowledge or already known to the researchers (e.g. the year a partnership was established), we did not include it. However, if the objective of the code is to demonstrate confusion about dates among respondents, it could be coded.
- If the information is already captured in the quantitative survey, e.g. if the quantitative survey asks whether villagers have experienced an increase in the number of elephants, there is no reason to code for this information in the qualitative data. If, however, the interviewees elaborate on the consequences of this, or add other kinds of information that go beyond the survey, it could be coded.
Analytical codes based on the quantitative survey
- We went through the preliminary findings of the quantitative survey to determine interesting trends, paradoxes and gaps that the qualitative data could help to answer. We then created codes which could help us to find these answers.
Analytical codes based on cross-cutting issues and emerging hypotheses
- Having conducted fieldwork multiple times, the research team members had already identified some findings that challenged current understandings in the literature. They had also developed ideas for interesting trends and paradoxes as well as hypotheses that might explain them. For each natural resource sector we worked on selecting key codes based on these hypotheses. The underlying idea was that the codes could help find the data needed in order to support, nuance or challenge the hypotheses. In addition, I prepared codes based on cross-cutting issues identified by the team during a previous debriefing meeting following the fieldwork. Using this approach enabled us to work closely with the data, which is a key factor to successful inductive research.
Analytical codes that arise while coding
- Once we had begun the coding process, coders suggested nodes that they found were missing in the codebook (discussed later).
The process of selecting approximately 50 codes to create the first version of the codebook took one day. The codes are key to the analysis. Identifying the most appropriate and interesting codes is therefore central to good analytical work and should not be rushed.
Step 4: Go through the Codebook
Once I had received all the proposed codes, (including parent nodes, potential child nodes, and descriptions for parent nodes and child nodes as shown Figure 3), I combined them into one codebook. We then went through the codebook as follows:
- I asked each member to read through the codebook and make comments.
- In a plenum session, we discussed each parent node and child node.
- This discussion was carried out for a whole day. This time frame was very important because it enabled us, amongst other things, to:
- discover synergies and cross-cutting issues
- agree on definitions and terms, notice and resolve misunderstandings
- challenge each other’s assumptions (e.g. could this be an example of a misunderstanding of a rule by villagers or is there a possibility that they pretend to misunderstand?)
- As a result of these discussions, we revised node names and descriptions, created new parent nodes and child nodes and deleted others.

This part of the process was important for creating a codebook as relevant and understandable as possible. Once we agreed on the first version of the codebook, I created an NVivo project and manually entered all the nodes from the codebook (no files were added yet). While NVivo allows the exporting of existing nodes as a codebook, it is, to my knowledge, not possible to import a codebook.
Step 5: Set Up NVivo Projects
As everyone had been introduced to NVivo’s general features and operating principles in earlier workshops, we did not have to spend a lot of time familiarizing ourselves with the software. I will not provide a detailed description of the technical aspects of the software here, as there are many useful tutorials available. Before setting up the NVivo projects, however, we ensured that everyone had the latest version of NVivo. It is furthermore an advantage if everyone works on either a PC or a Mac, as there are some known problems with merging projects coming from a PC and a Mac.
Each team member focused primarily on one natural resource sector in their research, and I asked the team members working on the same sector to jointly use one computer when setting up an NVivo project for their sector (e.g. all the researchers working on the wildlife sector sat together and created ‘NVivo Project Wildlife’ while working on only one computer). Each group got a copy of the NVivo project I had created with all the nodes from the codebook. Each group then added a structure of folders under ‘files,’ in which the qualitative data would be placed. However, at that point of time we had not yet imported the files with qualitative data.

Step 6: First Test-coding
We decided on a two-step test-coding process to ensure intercoder reliability. In other words, we assessed how similarly each coder understood and applied the codes from the codebook. Still working together on one computer, each group imported one qualitative data file (containing e.g. a key informant interview, a focus group discussion, secondary document or participant observation) into their project, coded it together, discussed and clarified which codes to use.
Step 7: Second Test-coding
After the first test-coding, each team member copied the relevant NVivo project and saved it on their own computer. They also added their initials to the project name, e.g. ‘NVivo Project Forestry MFO.’ After that, team members working on the same sector chose one qualitative data file and imported it into each member’s NVivo project. Then, each team member coded the data file individually without speaking to each other and compared the results afterwards. We repeated this process until the team members felt that they were coding in a similar way. It is, of course, unlikely that everyone will ever code in exactly the same way, no matter how much you train. This iterative repetition nevertheless helps to improve homogeneity.
Step 8: Coding Individually
Once everyone was ready to code individually, we proceeded as follows:
- The team members working on the same sector divided the qualitative data files between them. We used Excel sheets, as exemplified in Figure 1. Each qualitative data file was only coded by one person.
- When ready to begin coding a new qualitative data file, the coder would import that file, indicate in the Excel sheet that the file had been imported to NVivo and then start coding.
- Since we were all sitting in the same room, each team discussed questions related to coding as they arose. If a matter could not be resolved within the groups, we would discuss it in plenum the following day.

Step 9: Editing the Codebook
At the beginning of each working day, we discussed the possibility of adding new nodes that had come up the previous day, and that coders considered relevant. We discussed them in group sessions in order to clarify how to best name the nodes and formulate their descriptions. Sometimes we decided that the issue covered by the potential new code was already included in an existing node. Through these discussions we were able to continuously discover synergies and cross-cutting issues, clarify definitions and terms, and challenge each other’s assumptions.
Step 10: Working in Many Standalone NVivo Projects
It produces some challenges to work with various standalone NVivo projects at the same time and save them on individual computers. The final goal is to merge all the individual projects into one overall project. In order to ensure that this process works smoothly, we developed the following procedures:
New nodes
- It is easy to add new nodes to everyone’s projects. As described under Step 4, I had created an NVivo project that contained nothing else but all the nodes from the codebook. Whenever we agreed on new nodes, I would add them to the NVivo project and send the project to everyone. Each person would then import the project into their NVivo projects (merging the two). In order to make sure everyone had the latest version of nodes, I included the date in the name of the NVivo project I sent them.
Edit node names or delete nodes
When importing a project, NVivo simply merges everything. Changing node names or deleting nodes is therefore more complicated:
- If, for example, one person deletes a node and then later merges his or her project with the project of someone who has not deleted the node, the node will appear again.
- If one person changes the name of a node while another person does not and their two projects are merged, two nodes will appear – one with the old name and one with the new name.
- One solution is for everyone to send their project to a designated NVivo file manager who merges all the projects, makes the necessary adjustments, and then distributes a new version. However, due to various reasons this was not a feasible solution for us.
Editing files
If two projects contain the same qualitative data file and one person edits just one word in their version, NVivo will perceive them as two different files when merging the projects. For this reason, I asked everyone to not import a qualitative data file until they are ready to begin coding it. Hence, they did not import all files at once. Thereby we enabled coders to edit the qualitative data file while working on it until the point when they had to share their NVivo project with the others. An alternative solution is to ask coders to write comments in memos. In this case, the changes can be incorporated once the individual projects have been combined and before they are distributed again.
Step 11: Finishing the coding
I recommend finishing the coding process at a time when all coders are able to work together. If there is a lot of data to code, this may not be realistic. However, since participants will likely need different codes, it is important to code different types of interviews while everyone is together.
We decided to complete the process of coding after the end of the workshop in the following way:
Coding individually with deadlines
We divided the work between the researchers and set a deadline for the coding process to be completed.
New nodes
In the case that one or more of the nodes we established during the workshop are inadequate, coders should contact me with suggestions for new nodes. I will then distribute a new NVivo project with the new node architecture to everyone. By now, all participants should be able to import the NVivo project with nodes on their own. I will also distribute a new codebook with additional entries. We further emphasized the following:
- Coders should not add nodes on their own
- Coders should not edit node names on their own
- Coders should refer to the codebook to see full code descriptions
- Coders should remember to frequently back up their individual NVivo projects
Merging Projects
Once the coding process is completed, team members should merge the projects so that the research project ends up having one NVivo project for each sector as well as one for the whole research project. As I have mentioned earlier, it is possible to merge NVivo projects more frequently and then send the new versions to everyone. Thereby you can edit the project more extensively in the merged version before distributing it (in terms of e.g. changing node names, and editing files).
Classifications
Adding classifications, cases and attributes to the qualitative data files imported to NVivo can be very useful for the analysis. NVivo has very clear-cut guidelines for doing this.
Afterthoughts: Interdisciplinary Coding
NVivo is a useful tool for organizing qualitative data and making it more accessible. In addition to this, I found that one of the most rewarding aspects of coding was that it provided the researchers with a structure for discussing and analyzing the data together as a group. It also turned out to be a useful exercise for highlighting the nature of qualitative data and why it is important. As I mentioned before, NEPSUS is an interdisciplinary group of researchers of which some are not used to working with qualitative data. Throughout the preparation and the actual coding process, several of the researchers involved emphasized their changed perception of qualitative data. They pointed out that it had become clearer to them why qualitative data is important, and what sort of information can be acquired from qualitative data. This is, perhaps, the most important outcome of the workshop.
The process I highlighted in this blog post is by no means the only way of carrying out a coding process with NVivo. Every research project has its own challenges and characteristics, but I hope the readers who wish to do something similar will find it helpful.